Convolutions
1 Group convolution
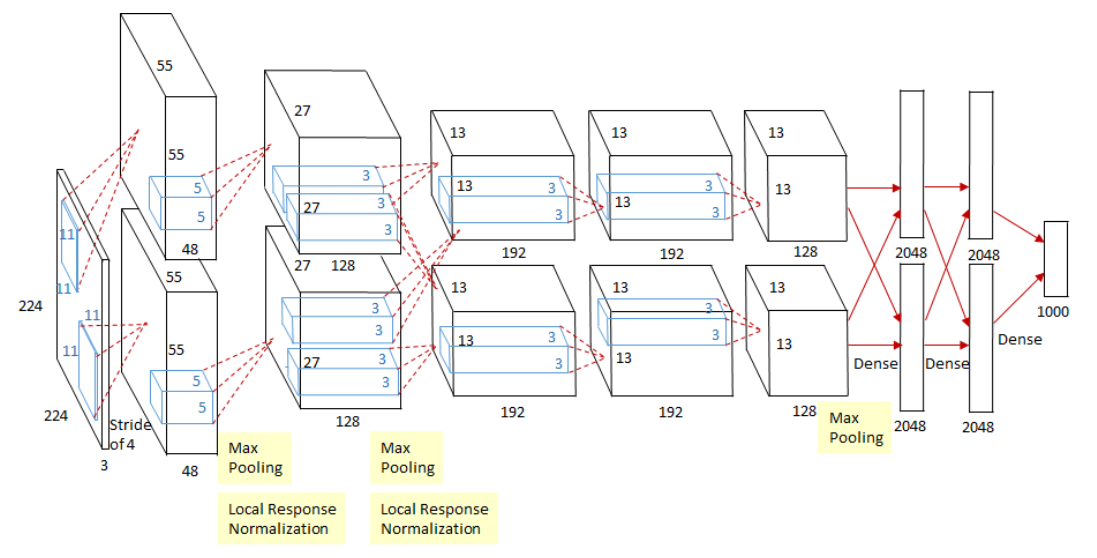
最早见于AlexNet,用来切分网络在两个GPU上训练,推广: ShuffleNet, extremely efficient for mobile devices
AlexNet:
Group conv:
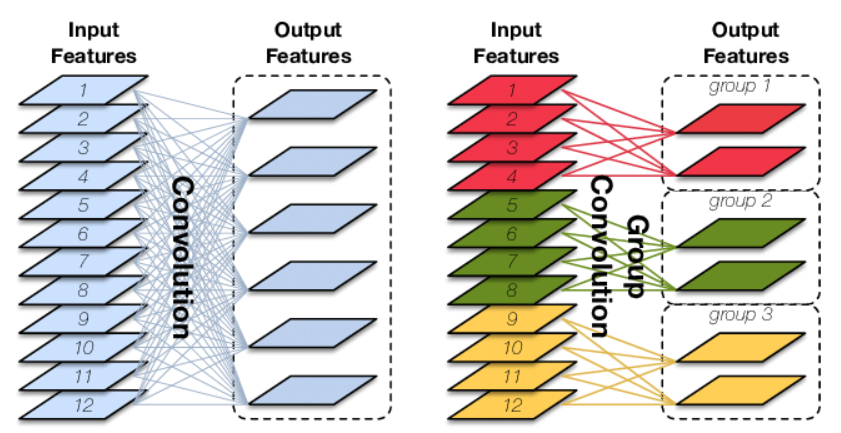
优势:
- 减少参数量,减少计算量
- Group convolution可以看成是structure sparse,相当于正则,在减少参数量的同时获得更好的效果
- 当分组数等于输入map数量时,等价于depthwise convolution,参数量进一步减少
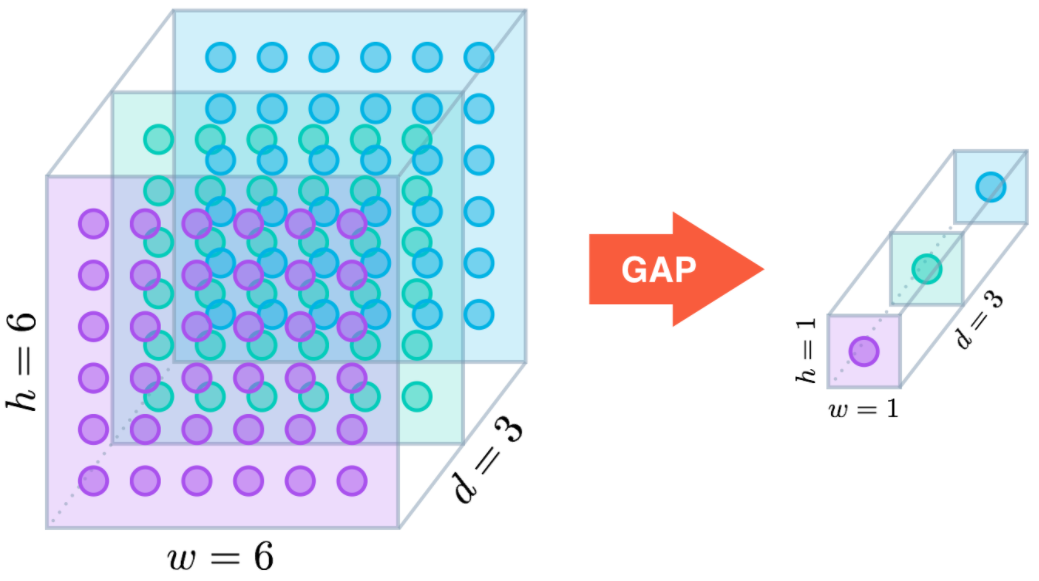
- 其它情况可等价于GAP等
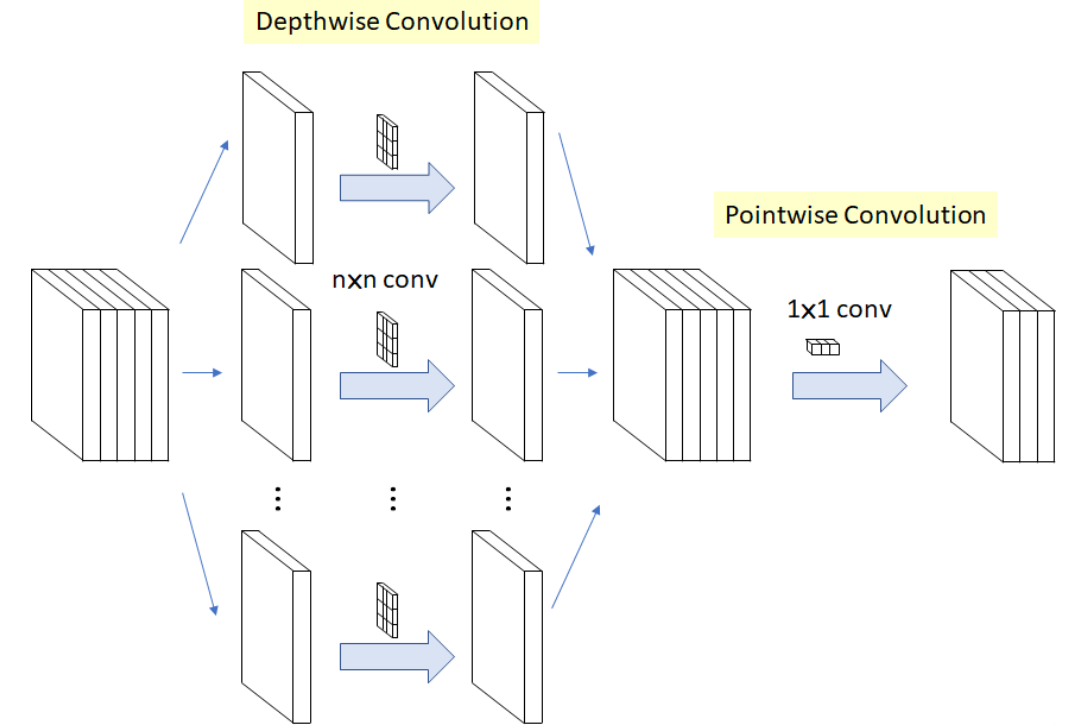
2 Depthwise (DW)/Pointwise convolution (PW)
提出: MobileNet, 提高训练速度与效率,speed&accuracy&efficiency
Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
-
Depthwise convolution:
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。
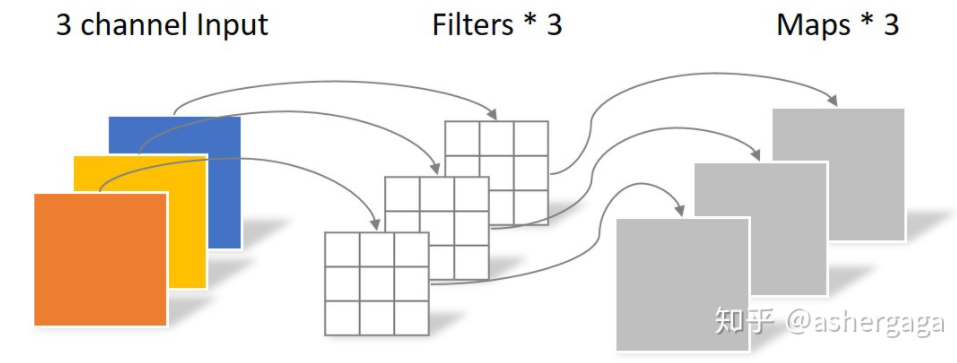
-
Pointwise convolution
Pointwise Convolution的运算与常规卷积运算非常相似(kernel size的区别) ,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。
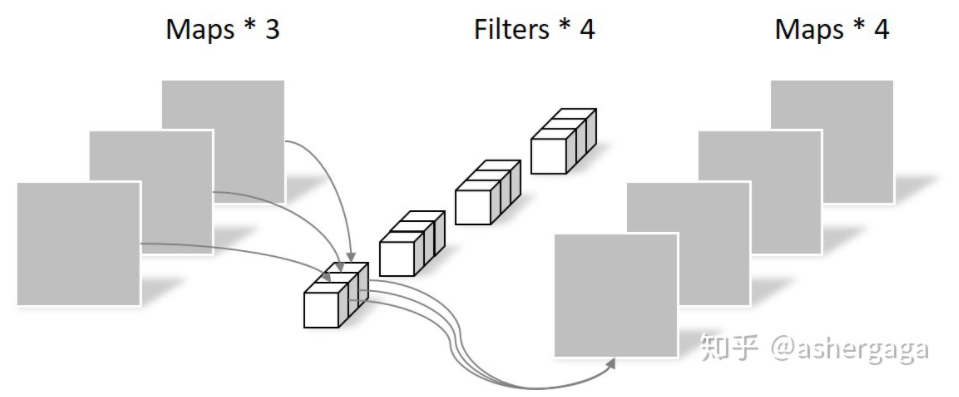
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
3 Inverted residual block && Linear Bottlenecks
提出: MobleNet-V2,improvement in terms of accuracy and speed
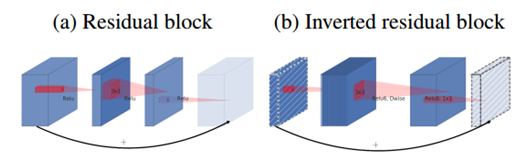
传统的residual block,先用1x1卷积将输入的feature map的维度降低,然后进行3x3的卷积操作,最后再用1x1的卷积将维度变大。
Inverted residual block先用1x1卷积将输入的feature map维度变大,然后用3x3 depthwise convolution方式做卷积运算,最后使用1x1的卷积运算将其维度缩小。注意,此时的1x1卷积运算后,不再使用ReLU激活函数,而是使用线性激活函数 (linear bottleneck),以保留更多特征信息,保证模型的表达能力。
4 Fire module
提出: Squeezenet, 实现模型压缩,减少参数量50x
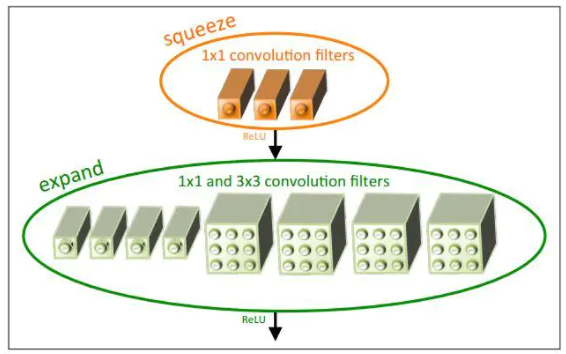
在Fire module中作者使用了三个hyper parameters用于表示它的构成。
s1x1表示squeeze layer filters的数目;e1x1表示expand layer中1x1 conv filters的数目,e3x3则表示expand layer中3x3 conv filters的数目。
因为在每个fire module内部s1x1要远小于e1x1 + e3x3,它们满足s1x1 = SR * (e1x1 + e3x3)。而SR称为缩减系数,在这里只有0.125。
5 Dilated/Atrous convolution
提出: Multi-Scale Context Aggregation by Dilated Convolutions, 常用于语义分割
VGG中的发现: 7 x 7 的卷积层的正则等效于 3 个 3 x 3 的卷积层的叠加,这样的设计不仅可以大幅度的减少参数,其本身带有正则性质的 convolution map 能够更容易学一个 generlisable, expressive feature space。这也是现在绝大部分基于卷积的深层网络都在用小卷积核的原因。
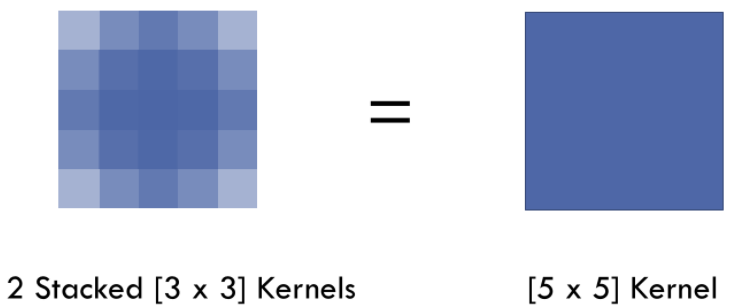
然而 Deep CNN 对于其他任务还有一些致命性的缺陷。较为著名的是 up-sampling 和 pooling layer 的设计。这个在 Hinton 的演讲里也一直提到过。主要问题有:
- Up-sampling / pooling layer (e.g. bilinear interpolation) is deterministic. (a.k.a. not learnable)
- 内部数据结构丢失;空间层级化信息丢失。
- 小物体信息无法重建 (假设有四个pooling layer 则 任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建。)
在这样问题的存在下,语义分割问题一直处在瓶颈期无法再明显提高精度, 而 dilated convolution 的设计就良好的避免了这些问题。
Dilated convolution优点:
内部数据结构的保留和避免使用 down-sampling 这样的特性。
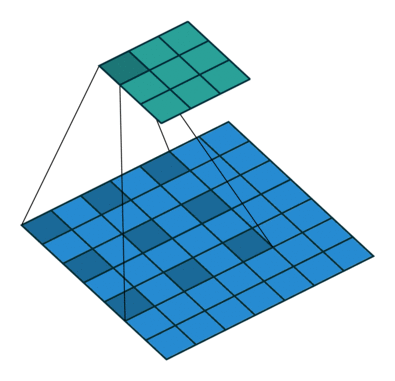
缺陷:
- The gridding effect, related to dilation rate
- Long-ranged information might be not relevent
图森组的文章的solution:Hybrid Dilated convolution (HDC)
- Dilated rate为质数或1
- 将dilation rate设计成锯齿状结构,例如[1,2,5,1,2,5]循环
- Mi=max[Mi+1 - 2ri, xxxx]
其它改进方法:Atrous Spatial Pyramid Pooling (ASPP)
基于港中文+商汤PSPNet中的Pooling module,ASPP在网络decoder上对于不同尺度上用不同大小的dilation rate去抓取多尺度信息,每个尺度作为一个独立的分支,最后合并,连接一个卷积层作为输出。这样的实际有效笔辩了在encoder上冗余信息的获取。
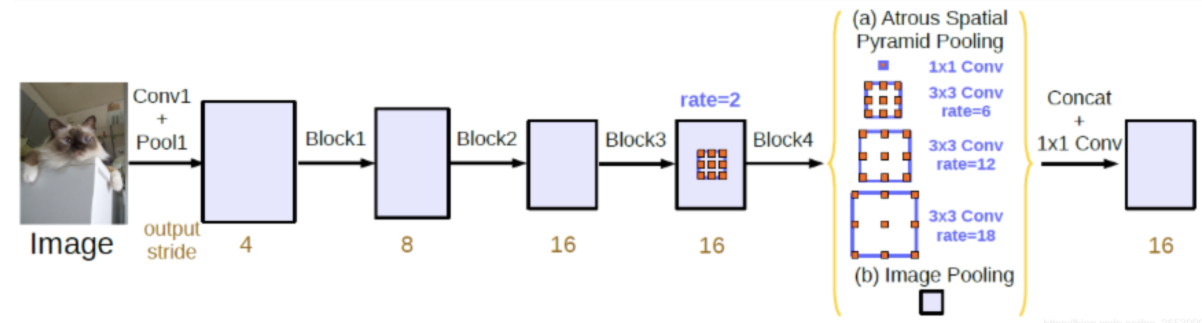
kernel中间的间隔为rate-1
通常做padding,空洞卷积后,输出尺寸大小与正常conv一致
假设kernel大小k=3,rate=16,则padding=rate=16
6 Fractionally-strided convolution
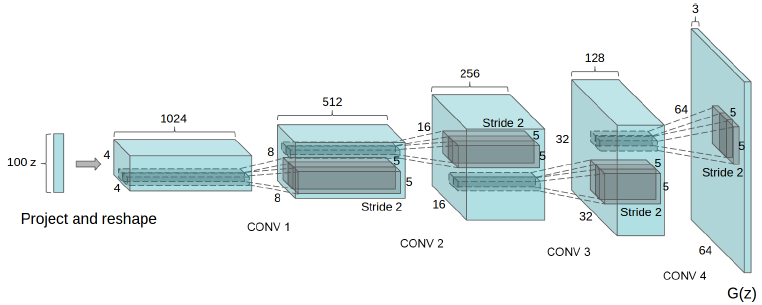
In DCGAN:
Figure 1: DCGAN generator used for LSUN scene modeling. A 100 dimensional uniform distribution Z is projected to a small spatial extent convolutional representation with many feature maps. A series of four fractionally-strided convolutions (in some recent papers, these are wrongly called deconvolutions) then convert this high level representation into a 64*64 pixel image.
I heard the term “fractionally- strided convolution” while studying GAN’s and Fully Convolutional Network (FCN). Some also refer this as a Deconvolution or transposed convolution. Transposed convolution is commonly used for up-sampling an input image.Prior to the use of transposed convolution for up-sampling, un-pooling was used. As we know that pooling is popularly used for down sampling input feature maps in CNN. Similarly un-pooling is the exact opposite process to up-sample. Like pooling, un-pooling also does not involve learning. However transposed convolution is learnable.
BP-learnable of transposed convolution
我们已经知道卷积层的前向操作可以表示为和矩阵CC相乘,那么 我们很容易得到卷积层的反向传播就是和CC的转置相乘。
反卷积和卷积的关系
反卷积又被称为Transposed(转置) Convolution,我们可以看出其实卷积层的前向传播过程就是反卷积层的反向传播过程,卷积层的反向传播过程就是反卷积层的前向传播过程。因为卷积层的前向反向计算分别为乘 C和 CT,而反卷积层的前向反向计算分别为乘 CT 和 (CT)T,所以它们的前向传播和反向传播刚好交换过来。
Fractionally-strided convolution 的stride大于1,正如下文transposed convolution示例图所示,fully-strided convolution的stride=1,input中间内部不插入0
7 project and reshape
According to GAN, project and reshape implementation including:
- Dense(100, 4*4*1024)
- reshape(4,4,1024)
8 Shift Conv
在Shift卷积算子中,其基本思路也是类似于深度可分离卷积的设计,将卷积分为空间域和通道域的卷积,通道域的卷积同样是通过1x1卷积实现的,而在空间域卷积中,引入了shift操作。
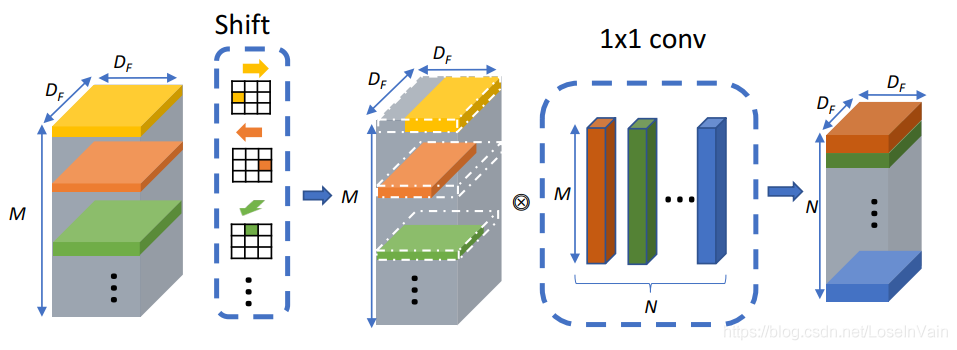
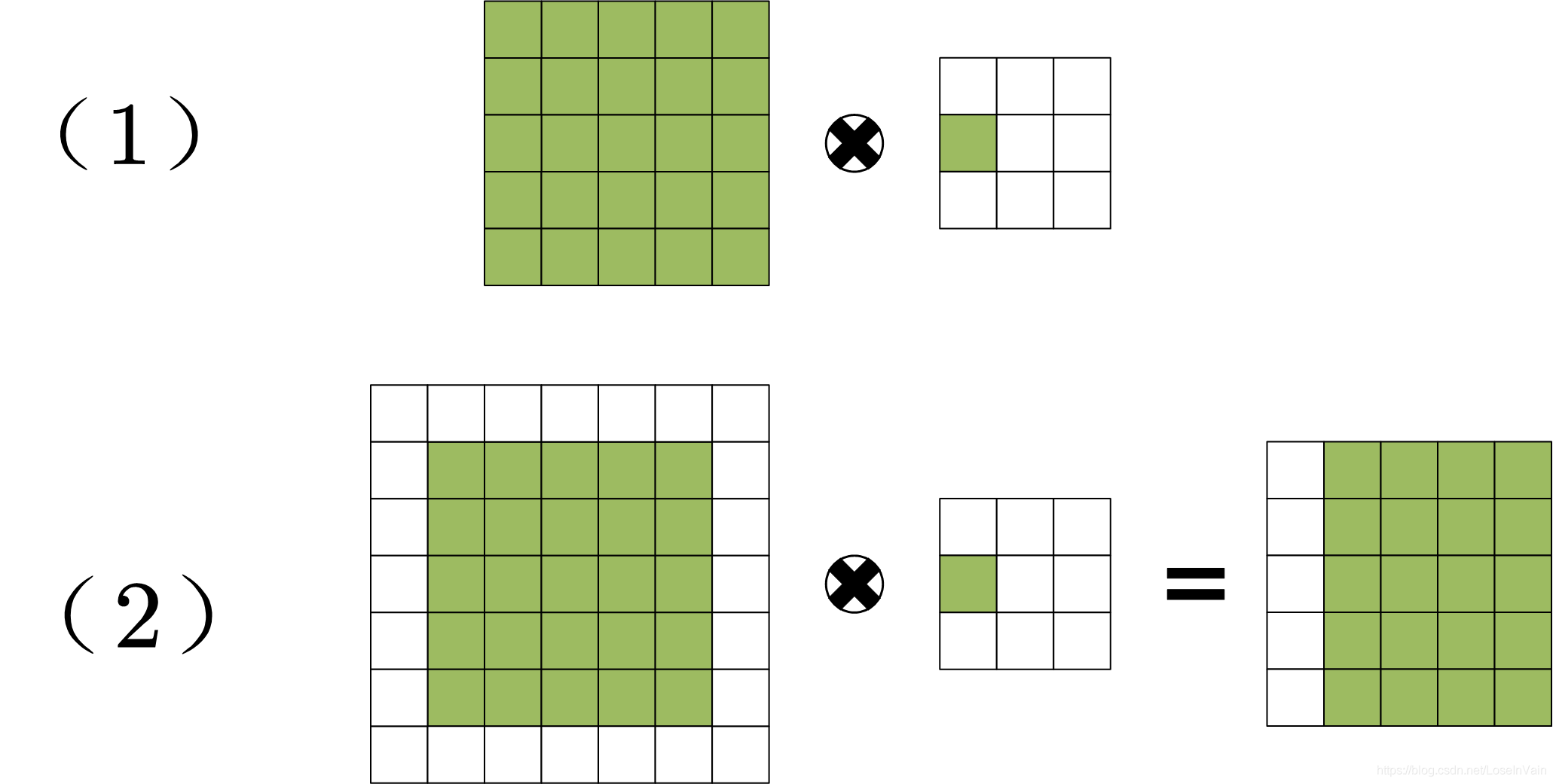
shift卷积的每一个卷积核都是一个“独热”的算子,其卷积核只有一个元素为1,其他全部为0。
对于输入的M个通道的张量,分别对应了M个Shift卷积核,如图中的不同颜色的卷积核所示。
我们把其中一个通道的shift卷积操作拿出来分析,如下图所示。我们发现,shift卷积过程相当于将原输入的矩阵在某个方向进行平移,这也是为什么该操作称之为shift的原因。虽然简单的平移操作似乎没有提取到空间信息,但是考虑到我们之前说到的,通道域是空间域信息的层次化扩散。因此通过设置不同方向的shift卷积核,可以将输入张量不同通道进行平移,随后配合1x1卷积实现跨通道的信息融合,即可实现空间域和通道域的信息提取。
Deconvolutions
1. Upsample
实现图像由小分辨率到大分辨率的映射的操作,叫做上采样(Upsample)。上采样有3种常见的方法:线性插值(1个方向),双线性插值(bilinear,两个方向),三次样条插值
2. Transposed convolution
反卷积,也叫转置卷积,它并不是正向卷积的完全逆过程
用一句话来解释:反卷积是一种特殊的正向卷积,先按照一定的比例通过补0来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积(padding包含stride参数,卷积核一般大于2*stride,下图stride等于2)。
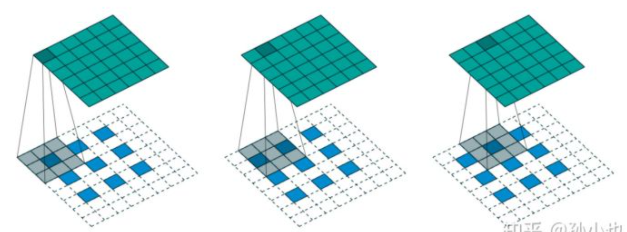
相对upsample,能获得更大的感受野reception field
3. keras.layers.Upsample2D
采用的是上采样方法
4. tensorflow.nn.conv2d_transpose
反卷积